System Landscape for Add-On Development
This is the second part of my answer to Christian Drumm's question What System Landscapes Setup to use for Add On Development? - and probably more of an answer to the original question than the first part. At the moment, many authors choose to place obscure references to Trifluoroacetic acid (or TFA for short) in their blogs, but since this post will be about rather fundamental aspects, I'd like to choose a different setting.

When thinking about software delivery and usage, it is a good idea to start with a rather simple model of provider and consumer. Separating these roles clearly makes it much easier to describe the requirements and expectations of the parties involved. I'm well aware that in the real world, the distinction between provider and consumer isn't necessarily that sharp. However, any intermediate role definition will likely contain aspects of a pure provider as well as a pure consumer - and, as you'll shortly see, complexity has a way of increasing, even with some simplifying assumptions in place. Also note that I'm leaving SAP out of the picture - one might describe SAP as "infrastructure provider", and that role in itself opens up a whole new universe of complexity.
So, to answer the question: let's assume we are on the provider side for now - the consumer will have to wait for yet another blog.

Make money, what else? To do so, we need to deliver our solution to the consumer, and that solution contains some ABAP-based software - otherwise, following this would be quite pointless. We're not using the software ourselves, we're just providing it to more or less anonymous customers. (This is actually important: it's a good idea to assume you know nothing about your customer's implementation details, since that will save you from dangerous assumptions with unpleasant consequences.)
Many details of the actual system landscape will depend on a number of decisions that are specific to the solution we want to provide. So, before defining the development and delivery process, we need to be able to answer a few questions:
- What are the dependencies of our solution - thinking in software components? SAP_BASIS certainly, but what else do we need? ERP? HR? CRM? What are the requirements of these dependencies? Which versions of the dependencies will we have to support?
- Which technologies are we going to use? Will we need to take special provisions for any of these?
- What kind of release and patch cycle are we planning for? How many concurrent major versions will we have to maintain? (Hint: Choose an odd number below 3 if possible.)
- What non-technical external factors exist that will have an impact on our release schedule? Will we have to follow legal changes and/or deliver on fixed dates to allow our consumers to meet regulatory deadlines? Will our customers have to update regularly anyway because of legal requirements - and if not, can we convince them to do so anyway or will we have to support ancient patch levels of our software?
Obviously, we can't answer these questions in detail for the hypothetical provider we're considering right now, but the implications of each decision should become clear during the course of this discussion.
We won't be discussing general good practices of software development like unit testing, integration tests, documentation and the like here. These aspects are of course very relevant to producing a stable, maintainable product, but we'll assume our developers know about that and won't need to be reminded times and times again. However, we need to remember that we need a working environment for many of these tasks, and that includes both the correct versions of our dependencies as well as a usable configuration. How will we need to configure the dependencies before we can start building our own software, and what configurations will we need to test the various ways our customers might use the software? Again, we can't answer that for a hypothetical solution, but you get the idea - there are some rather time-consuming activities lurking in the dark of an unanswered question.
For the following discussion, I'll assume that we'll use the Add-On Assembly Kit (AAK) to deliver the ABAP software components. If you're not entirely sure why, you can find my personal view on this topic here. It certainly doesn't hurt to know in detail how the AAK works, but we don't have time for that, so here are the basic ideas you need to understand the following discussion.
- With the AAK, you deliver software components (think table CVERS, SAP_BASIS). Physically, you'll ship a SARarchive that contains a PAT file which in turn contains the actual package files (starting with SAPK-). If you think of these packages as transports with additional functions on top, that'll do for now.
- You're free to use transports within the system landscape. At some point, you gather all the stuff you want to deliver in a central location (system) and perform your unit and integration tests (not covered here). Then, you decide what exactly is to be shipped, perform some additional checks and create the package files. This happens using the so-called Software Delivery Composer (SDC) and results in the SAPK files.
- The package contents are then turned into deliverable PAT files using the Software Delivery Assembler (SDA). In this step, dependencies and other attributes are added to the package files to produce PAT files. The PAT file names consist of the assembling system ID, installation number and a sequential number.
- The SAR files have to be packaged manually (or using some custom program). These are just archives that can be uploaded and installed more conveniently by the customer.
- The AAK is able to produce different kinds of packages for different scenarios that our customers might encounter. The most important ones are packages for initial installation (contains the current versions of everything), upgrade (only contains the changes), release upgrades (similar, but including release-specific changes) and patches (bug fixes, no new objects).
But enough of the asides - the question still is not answered: What do you want?
- If you're a developer, you'll want to spend as much time as possible working on cool new stuff without that pesky delivery infrastructure getting in the way.
- If you're responsible for testing and support, you'll want a dedicated system for every supported combination of versions and patches (and probably even separate systems for Unicode and NUC as well) for instant testing capability and full coverage of all possible installation scenarios. You'll want to find the ugly bugs before the software is delivered, and if systems needs to be broken at all - well, better not use the customer's systems.
- If you're the CEO, you want as few systems as possible. These things don't come for nothing, you know?
- If you're a responsible CEO, you'll want whatever is required to deliver the quality and performance the customers request - but nothing more than that.
And if you're the delivery manager, sitting right in the middle...?

Nononono, not so fast. You're responsible for getting our software to the consumer in one piece and without damaging our (bad) or their (VERY bad!) system, so you'd better step up on the understandings.
AAK-based delivery requires at least one delivery system for each SAP_BASIS release supported. We won't exactly need a separate delivery system for each patch level, but if significant changes happen (think 7.40 SP 05), different delivery systems might be required. That is, unless we can either postpone the installation of that patch in our delivery systems until all customers have that patch level installed (e. g. because it's part of some SP stack that contains legal adjustments) or simply raise the system requirements we impose on our customers. Similarly, if different releases or sufficiently differing patch levels of our dependencies (like ERP or CRM) are required, different test and delivery systems might be a good idea - but more about that later. (Remember the initial questions? As you see, it starts to get fuzzy, and we haven't sketched a single system landscape yet.)
Now what's a delivery system in this context? It's the source system of the technical installation packages - this is where the SDC stuff happens, and the SAPK package files get exported from here. It's usually a bad idea to deliver from the development system - or rather, to actively develop within the delivery system. If we allowed that, we'd probably have to lock out all the developers during a delivery process - or risk someone carelessly breaking the assembly process. Also, a development system usually contains local test objects, internal tools and more often than not some rather imaginativecustomizing introduced by the developers to reproduce some strange condition or try out a new feature. We don't want that ending up in our installation package, and we don't want anything in our installation package to accidentally depend on any of that stuff (think of a data element /FOO/BAR that is to be delivered, but still depends on a domain in $TMP).
The usual and indeed most simple answer to that is to separate at least the development from the delivery and have different systems for that. A reasonable approach would be to combine the test and delivery environment in one system (but use separate clients for testing - that also allows for different testing environments). Developers develop and release transports as usual, and these transports are imported into the delivery system. Whenever a delivery is required, you'd impose a transport / import freeze on the delivery system, perform the tests and compose the packages, while the developers can keep on coding in their separate development system. This also has the advantage that transports can be used to collect and group the objects that have changed and need to be delivered.
When assembling the PAT files during the delivery process, you will have to enter some additional conditions and prerequisites that will be contained in the delivered software and checked during the installation. It goes without saying that anyone can - and given enough time, will - make mistakes, so it's very sensible to double-check these import conditions by performing a test installation. (It's also mandatory for the certification which is in turn mandatory to get the AAK.) We will also want to check various different upgrade paths (will these fancy data migration tools actually work?) and probably provide an estimate on the total installation time. Now obviously, we can't use either the development system or the delivery system for that, since our software component already exists there and we don't want to break anything. No, we need a "vanilla" system that we can use to perform a test import. This had better be a virtualized system so that we can take a snapshot, perform the test installation and then revert to the saved state. Frequently, we will want to perform at least two test installations (fresh installation and upgrade from the latest version), and in some cases, it might be good to have systems with various releases and patch levels available for testing. These systems are usually not customized at all, and no functional testing takes place there - that should have happened before the delivery to keep the number of delivery iterations small. Also, with the number of installation test systems rising, it becomes a pain in the a...natomy to keep them all updated and customized correctly. These systems are simply targets to verify that we've produced an installable package.
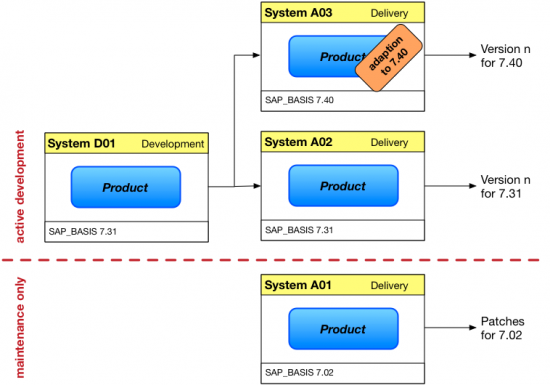
So now that we have a basic understanding of the systems we need, let's see what that landscape will look like:
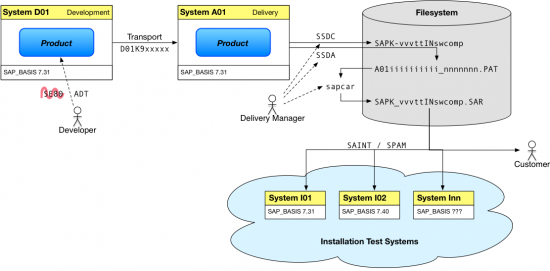
Now this looks nice and compact, but don't hold your breath - we're not quite finished yet. First off, there's a slightly less-than-obvious problem regarding the maintenance of our solution. Once the delivery of, say, version 3 has been completed and customers are busy installing the new software, the developers in turn will start to work on new features in preparation of version 4. Thus, once transports from D01 to A01 are enabled again, the delivery system won't stay in the state that was used to assemble the delivery for very long. Since the delivery system no longer resembles a hypothetical customer system (and it might even be occasionally broken while development is still ongoing), it is no longer possible to reproduce issues or test fixes with the exact same software that the customer has installed. That's bad, especially if some particularly nasty bug escaped our collective attention during testing. How can we prevent this?
The obvious solution would be to not import any transports until right before the delivery date. However, that's generally considered a bad idea, since lots of issues are usually identified by transporting and importing (e. g. missing dependencies, accidentally $TMP'ed objects and other basic errors), so delaying this is not desirable. Also, sometimes one needs to release transports for various reasons, so a queue of transports might pile up. Having to fix broken transports weeks or months after they have been released might throw a spanner right in our delivery schedule. So what's the alternative if we need the capability to continuously support older versions of our product? Yup, another system - or another line of systems. These maintenance systems will usually be copies of the delivery system that are already fully customized for tests. Every time a new version is released, a copy of the delivery system is used to create a new maintenance system, and once a legacy version is no longer supported, the maintenance system is shut down.
These maintenance systems also have another use. As the saying goes, after the release is before the release - the development continues, new features are invented and transported, virtual trenches are dug and stuff is prepared to be reworked, refactoring is happening all over the place. The development team is happily hacking away, until - a bug. It needs to be fixed - and fast. However, the objects affected by the bug are already in a different state than the one that was delivered, and they are no longer compatible to the old version. And even if that particular part of the software was not affected, the entire product might not be in a usable and testable state right now. Obviously, we can't use our development system to produce the fix. Again, the maintenance systems saves the day: The developers can implement a fix in the maintenance system and test it there, and we can deliver a patch from that system. Note that to implement the fix, the customer will either have to import the latest patch, or implement the correction manually - there's no note/correction support for 3rd party products that I'm aware of.
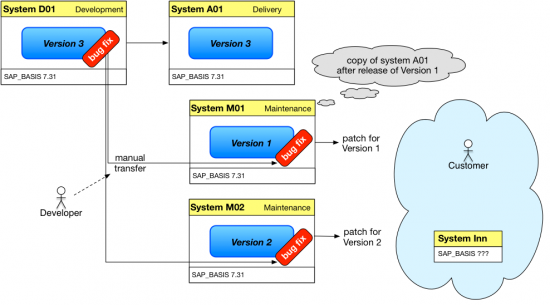
It should be noted that, under certain circumstances, it is possible to work without maintenance systems. Whether we can use this approach basically depends on stability of our software (or rather the lack thereof) and the time-criticality of the fixes we might need to deliver: If our software stays relatively stable most of the time and/or consumers can tolerate longer wait times, we can trade in development flexibility for system landscape simplicity:
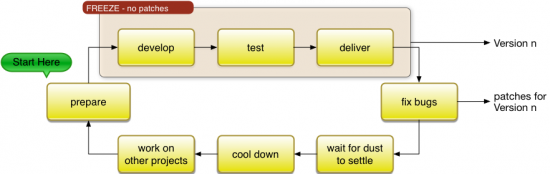
As you can see, during active development and testing, no patches can be released, and customers always need to upgrade the entire software to get the latest patches as well as functional upgrades that they might not be interested in at all. While this might be a perfectly reasonable approach for some situations, it might prove utterly useless for other situations.
So far, we have only considered one active development stream with occasional fixes to the previous version. Theoretically it would be possible to release version 1.0 and start maintaining it, then start work on improving (not just fixing!) the software producing a line of 1.x upgrades while at the same time starting work on a completely new track, producing version 2.0. This might sound like a good idea, but in practice, it rarely is: The ways to screw up increase exponentially, and it increases development complexity and testing effort a lot - not just for own development and testing personnel, but also for our customers. This approach rarely provides any business advantage for either the provider (that will be us) or the consumer (that will be the ones that will - or won't - be paying us). A true ?REDO FROM START is rarely needed, and from my experience, we'd be best off treating this situation as "we're starting an entirely a new product under a different name that has a different code base and does not depend on the old one". So, no boom.

Pessimistic though this approach may be, it does have its merits. Because - well, we're still not there yet. So far, we have only considered the versioning and maintenance of our own solution. As we've already stated in the introduction, we'll usually need to provide software for more than one target release. To simplify the situation, let's focus on the SAP_BASIS release, since that's what the AAK requires anyway, although the same scheme might also apply for other dependencies. Again, resolving this situation requires the use of multiple delivery systems and installation test systems, but with a different pitch: We're now trying to produce the very same software (including patches) for different platform versions. Simply multiplying the development systems as well will get the developers to launch pointy objects in your general direction, so that's not an option. So - can't we just centralize the development system? We can, but that leads to another question: What's the baseline?
At this point, we need to take a short detour and think about transporting up and down the stream - that is, transporting development objects to a higher or lower target release. Transporting "up" is usually possible and not very problematic - stuff developed on lower releases will usually just work (at least technically) in higher releases. So, a SAP_BASIS 7.02 development system supplying objects to a 7.40 delivery system is usually not a problem. We might therefore choose the lowest target release we need to supply our product for as the baseline. However, this limits developers to relatively old version of the development environment (e. g. it might restrict them from using ADT). While this certainly is not favorable, from my experience, many developers tend to tolerate that if they understand the perils of the other option: Keep the development system on the highest release supported and transport objects downstream. This is not supported officially and liable to break - both technically during the transport process as well as within the coding itself. From a technical perspective, newer releases usually contain more options, larger database tables, more sophisticated tools - and transporting objects made with these new tools that already have some of the new options set and additional fields filled to a lower release that doesn't have these options and fields might have any of a number of undesirable side-effects. As for the coding - imagine a developer using the fancy new operators introduced with 7.40 SP 05 on the development system, only to find out that these won't work on the lower releases. Or imagine someone using a cool new class to create UUIDs, random numbers or some other API that doesn't exist on lower releases. This is not fun at all. SAP actually works that way, developing on the new release and then down-porting functions if necessary, but SAP does have other tools and more sophisticated system landscapes (and a lot more people!) at hand. Smaller development shops don't have that option and are usually better off with up-porting, even if that restricts the toolkit available to developers - so we'll go with that option.
Now let's consider the software itself. No product is an island - there are always connections with the platform and surrounding components. The question is - does any of these connected components change across releases in a way that forces us to write our software differently on different releases? If that is not the case, if our software stays the same on all target releases, that's good: we only need one development system, supplying transports to multiple delivery systems. At greatest need, small patches required for individual target releases might even be implemented in the delivery system.

However, if this is not possible because the software needs to be adapted substantially depending on the target release, it's a good idea to organize our software to separate release-independent parts from release-dependent ones. In this case, it also pays off to add release-dependent adaption systems between the central development system and the delivery systems.
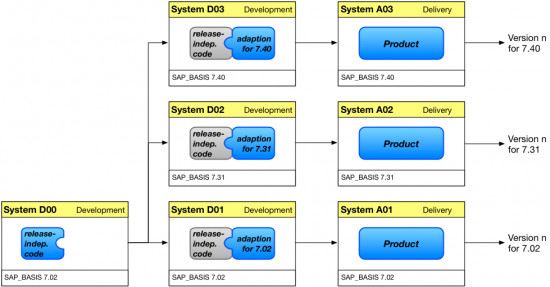
Additionally, in order to allow the developers at least access to some of the newer technologies, it might be an option to place a "cut off" point at some release: On any release below that, consumers get maintenance fixes only, but no new features or other active development happens on the legacy releases. This will allow us to raise the baseline release, at least a little.
Finally - we're almost there, hold on - there are two more systems. One that's probably required: As far as I know, you need a Solution Manager installation in order to install and maintain the system landscape. Unfortunately, I know next to nothing about the Solution Manager. What I do know that it might be beneficial to add yet another system to the landscape that is used to centrally assemble the delivery packages (the SSDA step that turns SAPK files into PAT files). There are a number of reasons that might be a good idea:
- It's very handy to have a single system that knows about all of the packages, e. g. to populate download portals or other delivery software.
- If delivery systems get added and removed periodically, package detail information might get lost. If that information is kept in a central location, there's no danger of package data becoming unavailable.
- All PAT file names contain the SID of the system that created the file. For the customer, it's more consistent if there's only one system name appears in the delivered files.
- Package assembly and attribution is somewhat tricky - you wouldn't want the average developer to mess around with the package attributes.
Also, that system might be used as the TMS domain controller, to provide a central user administration (CUA) landscape or to produce the roles that are then distributed throughout the system landscape.
Okay - now that we've collected all of the puzzle pieces, let's put together a system landscape for a single-stream product development. Let's assume that we'll need to apply non-trivial adaptions to the target releases we provide software for, and that we need to maintain and produce patches for the last two versions we released. We'll need to actively support SAP_BASIS releases 7.31 and 7.40 with 7.31 as our baseline, while maintaining the infrastructure to provide patches for out legacy 7.02-based versions. While we're at it, we might already prepare the plans for adding the new 7.50 release to the landscape.
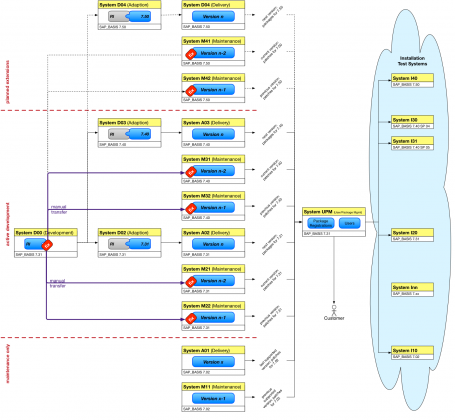
Now isn't this nice? 21 systems and counting, not including the SolMan...
My key points:
- You need a clear understanding of your customer's expectations and technical limitations to decide on the best possible strategy and system landscape layout.
- You also need a competent basis administrator (who is NOT billing by the hour!) and/or someone with combined administration and development skills in-house to maintain and optimize the systems.
- Trivially, you need funding for the system landscape. As far as I know, SAP will license by development user, not by system, but you need the infrastructure anyway.
As a reward, you get the ability to deliver and maintain ABAP products with high quality standards and reliable, verified delivery processes while keeping customer risk and effort relatively low.
As always, careful planning and a lot of thought beforehand is in order:

- 6428 reads
Theme by Danetsoft and Danang Probo Sayekti inspired by Maksimer